HSR: El Estándar de Disponibilidad
SAP HANA System Replication (HSR) es el mecanismo nativo para garantizar la continuidad del negocio. A diferencia de soluciones basadas en almacenamiento (Storage Replication), HSR opera a nivel de base de datos interpretando los Redo Logs. Esto permite una validación lógica continua de los datos en el nodo secundario, eliminando el riesgo de replicar corrupciones de bloque físico.
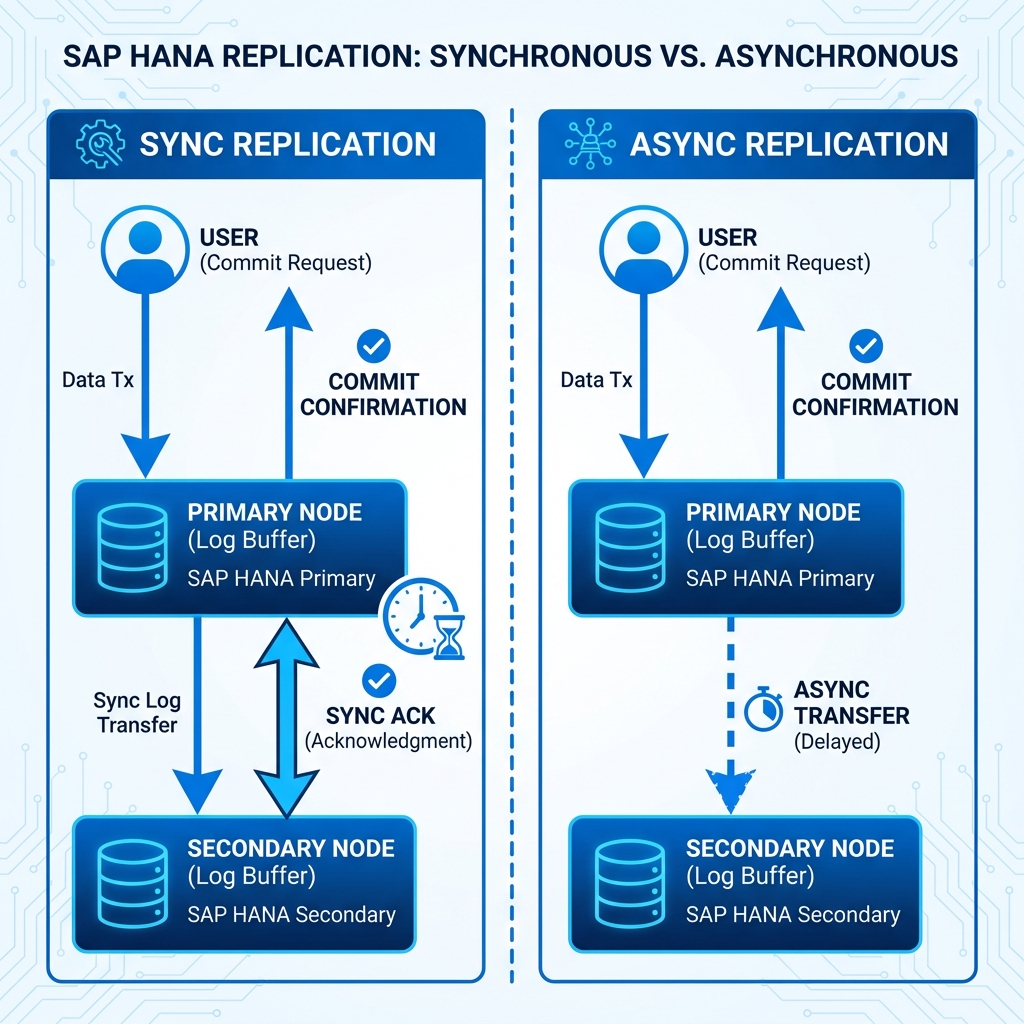
Modos de Replicación (Replication Modes)
La elección del modo define el RPO (Recovery Point Objective) y el impacto en rendimiento:
SYNC (Synchronous)
El modo paranoico. La transacción primaria no se confirma (COMMIT) hasta que el secundario confirma que ha escrito el log en su disco. RPO = 0. Riesgo: Si el enlace cae, el primario se congela (hang) hasta el timeout.
SYNC-MEM (Synchronous in Memory)
El equilibrista. El primario espera solo a que el secundario reciba el log en memoria (sin esperar disco). Reduce la latencia drásticamente mientras mantiene RPO = 0 siempre que no fallen ambos nodos simultáneamente.
ASYNC (Asynchronous)
El corredor de fondo. El primario envía y olvida. Ideal para escenarios de Disaster Recovery (DR) a cientos de kilómetros donde la latencia de red (>5ms) haría inviable el modo SYNC.
Modos de Operación (Operation Modes)
Estos modos definen qué se envía y cómo opera el nodo secundario:
- logreplay: El estándar moderno. Solo se replican logs. El secundario los "reproduce" continuamente. Ahorra 90% de ancho de banda frente al método antiguo.
- logreplay_readaccess: Convierte el nodo secundario en un sistema Active/Active (o más precisamente, Active/Read-Enabled). Permite conectar herramientas de BI al puerto SQL del secundario para ejecutar reportes pesados, liberando carga del primario. Requiere licencia adicional.
- delta_datashipping: Método legado. Envía snapshots de datos cada 10 minutos. Tiempos de recuperación (RTO) más largos ya que la memoria debe cargarse desde cero tras un takeover.
Configuración de Red y Multitier
Una arquitectura robusta de HSR requiere una red dedicada. Se recomienda configurar
system_replication_hostname_resolution en el global.ini para segregar el
tráfico de replicación (masivo) del tráfico de clientes y aplicaciones.
Multitier Replication
SAP soporta encadenamiento de replicación (A → B → C). El diseño común para empresas globales es:
Nodo A (HQ) --[SYNC]--> Nodo B (Data Center Local) --[ASYNC]-->
Nodo C (Región Remota).
Esto proporciona HA local instantánea y protección contra desastres geográficos simultáneamente.
Gestión de Clusters y Takeover
En entornos críticos, HSR se gestiona mediante software de Cluster (Pacemaker/Corosync en Linux). Para evitar el temido "Split-Brain" (ambos nodos creyéndose primarios), se configuran mecanismos de STONITH (Shoot The Other Node In The Head) que apagan físicamente el nodo fallido antes de promocionar el secundario.
Los administradores usan Python Hooks (librería SAPHanaSR) para que el
propio HANA notifique al cluster cuando cambia su estado interno, permitiendo failovers automáticos en
segundos.
Comandos Esenciales
hdbnsutil -sr_state: Estado detallado de la replicación.hdbnsutil -sr_takeover: Promocionar manualmente el secundario a primario.hdbnsutil -sr_register: Registrar un nodo como secundario (borra sus datos locales).
Preguntas Frecuentes (FAQ)
¿Cuál es la diferencia entre los modos SYNC y ASYNC?
En SYNC, el primario espera la confirmación del secundario antes de dar el commit (RPO=0). En ASYNC, el primario envía el log y continúa sin esperar, ideal para distancias largas.
¿Qué es el modo logreplay?
Es el modo de operación más eficiente donde solo se replican logs de transacciones que el secundario "reproduce" en memoria, minimizando el tráfico de red.
¿Qué significa STONITH en un cluster de HANA?
Significa "Shoot The Other Node In The Head". Es un mecanismo de seguridad en clusters HA que apaga físicamente un nodo fallido para evitar el estado de "Split-Brain".
Páginas relacionadas
Referencias clave para administración:
Monitorización Avanzada para vigilar el lag de replicación.
Backups y Recovery para complementar la estrategia de HA.